note:Unicodeで遊ぼう
そもそもUnicodeとは何なのかといいますと、ものすごくざっくり言えば「地球上のありとあらゆる文字を集め(ることを目標とし)た巨大な一覧表」です。とにかくものすごい網羅具合で現在13万6690文字、そして理論上は111万2064文字を収録するものらしいです。すごい。これだけあればどんな難しい外字でも大丈夫。
今我々が小説を入力するのに使用しているUTF-8というものは、このUnicodeに収録されている文字なら全て使えるモードのことです。以前のSHIFT-JISなどのモードではもっと貧弱な文字数しか扱えなかったので、現在はUTFが主流になりつつあります。
一覧表ですから全ての文字に番号が振ってあります。この番号のことをコードポイントといい、これが分かっていればどんな文字でも呼び出せます。例えばひらがなの「あ」はU+3042、☃(ゆきだるま)はU+2603です。ほんとにこういう字まであるんです。
しかし逆にある文字についての情報が知りたい時があります。そんな時の強い味方がW3CのRichard Ishidaさんの作った「UniView」です。
使い方は簡単で、右上のボックスに調べたい字を入力して↓を押すだけです。左下に出た字をクリックすると右側に詳細な情報が表示されます。
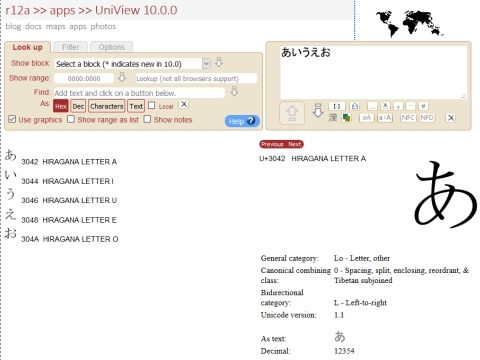
また☃のようにどう入力したらいいのか分からない字は、左上の「Find」のフィールドに読みや意味(ただし英語で)を入力し、「text」を選択することで探すことができます。今はsnowmanと入力したので、三種のゆきだるまが出てきました。
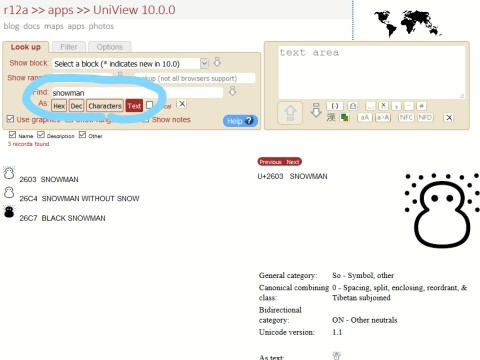
文字フェチの筆者はこのようにいろんな字をカチカチしているだけで楽しくて時間を忘れるんですが、本題はここからです。
Unicodeには文字を種類・国ごとにグループ分けするブロックというものがありまして、これが前項で操作していたものになります。
Univiewでは一番左上の「Show Block」からブロックを選べばそこに属する字が全部表示されます。文字通り全部表示しようとしますので、間違っても(big!)と書いてあるところは選ばないでください。(CJK Unified Ideograph=ほぼ漢字全部、とか)
前項で欧文扱いにしたかった主要なアクセントつき文字はEuropean Scriptの中の「Latin-1 Supplement」に入っています。左上のドロップダウンリストだと「Latin, Basic & Latin-1 Supplement」として普通のアルファベットと一緒に表示されちゃうんですが、右側に出た情報からリンクを辿ればSupplementだけが出てきます。
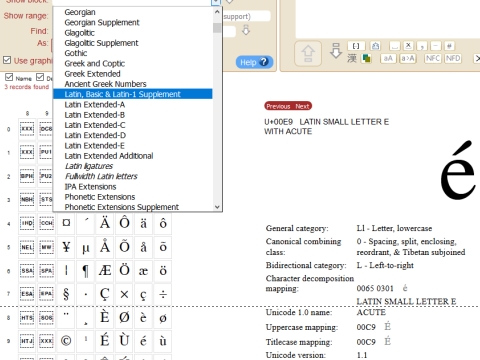
そんなに突飛でもない、見たことあるような字や記号が多いですね。むしろこれアルファベットに含まれないの?という感じですが、そのへんのことは昔々コンピュータが128文字しか扱えなかったころのお話に遡ってしまいますので、興味のあるかたは自分で調べてみてください。
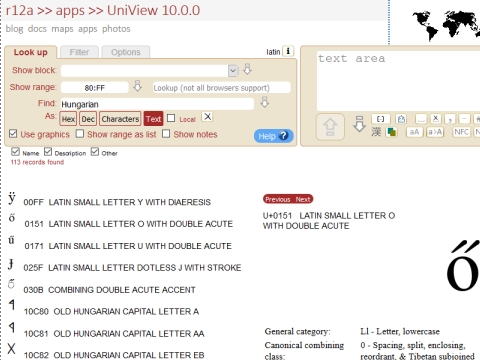
さて、ブロックの見方は分かりました。今例えば皇妃エリザベートの小説かなんかを書いていてハンガリー語を欧文扱いしたいとします。
左上に「Hungarian」と入力すると、こんな結果になりました。ダブルアキュートのついた字とダブルアキュートそのもの、あとはハンガリーの古代文字ですね(かっこいい)。
ő(U+0151)をクリックしてみるとデータが現れて、Unicode blockのところで「Latin Extended-A」に属していることがわかります。As Text:としてグレーになっているところがコピペ用で、ここからコピーすればそのまま他のエディタなどに正確にペーストできます(エディタ自体がUnicodeに対応していれば)。
こんなふうにUnicodeの意味を知ってUniViewを使いこなせるようになるといろいろ便利ですので、是非触ってみてください。
ちなみにUnicodeの利点については既に正規表現のところでもちょろっと触れていて、あそこで言った新しい文法というのがこのUnicodeプロパティ1に対応しているかどうかになります。対応していないと検索・置換が煩雑になるので、筆者は完全対応しているMeryをしつこく勧めていたのでした。
参考
- Unicodeプロパティとブロックとスクリプトの厳密な違いが分かってないです。どなたかご教授ください。 [return]